放逐Excel:将Emacs、Coreutils和Octave用于学生的作业成绩管理
我一直不大喜欢Excel,所以一直尝试用其他软件代替Excel。
Excel的优缺点及替代思路
既然要替代Excel,首先得明确Excel的优缺点。
Excel的优点有:
- 易用。
- 功能全面,也可以数据处理,也可以画图。
- 和Word等办公软件紧密结合。
Excel的缺点:
- 批量处理文件不方便。当然可以用宏,可我没用过,也没见人用过。
- 画的图不好看。
- 使用私有格式,不开放,不利于迁移和数据交流。
而用Emacs+Coreutils+Octave的组合,易用性差了很多,批量处理的能力提高了,而且可以借助Octave自由的画出想要的图。
需要说明的是,基于Emacs的org-mode可以实现本文的功能,但我觉得“over-engineering”了,不喜欢。Excel也不是一点都不用,如果是轻度使用,比如用于输入数据,在保证保存文件格式是通用的情况下,也可以。
用Emacs+Coreutils+Octave实现Excel的功能
基本编辑
就像上面说的,用Excel进行编辑也很好,如果用Emacs的话,如不借助专门的包(也不好用),编辑电子表格的数据不简单。如果只是对数据进行简单的编辑,借助Emacs方便的宏功能可以相对容易的批量处理。而且,现在Emacs在区域编辑(rectangle)方面功能也还好。
这里用Emacs不是必须的,可能更多的是出于习惯,谈不上替代Excel。希望我的叙述不至于让Emacs粉丝失望。
合并数据
实例:从某作业系统可以导出学生的作业成绩,但排序是乱的,而且同一次作业有些同学没交,需要特别处理。我想把多次作业的成绩汇总到一块。
分析:用Excel借助排序、筛选似乎也可以实现目的。
这里我用Coreutils里的join程序(join的手册)结合awk、sort和Emacs来实现数据合并。
首先准备数据。可以导出,可以复制,获得数据用Tab分隔,形式类似:
1 | 1711005047 袁小飞 2018年5月7日 21:47:26 3.0 李洁 教学班 查看 |
这里是复制的,格式不好,首先删空行,操作是M-x flush-lines RET ^\s-*$ RET,原理写过不再赘述。
删空行后,还需要提取出我们需要的数据。第五列成绩肯定是需要的。除此之外,可以保留第一列的学号。我用awk把需要的提取出来,在Emacs里的操作是:首先选中文字,然后C-u M-| awk '{print $1 "\t" $5}' RET。这里把选中的文字用awk处理,结果再插入,相当于替换了原有的文字,结果如下:
1 | 1711005047 3.0 |
因为join需要数据是排序好的,我们再排序一下,方法是选中文字后C-u M-| sort RET。其实这一步和上面一步可以合并。最后得到的结果保存成文件就可以,比如1.txt。这样的作业有很多,依次操作,可以得到很多的文件。你们可能觉得操作太繁琐了,可因为这些操作全部是用键盘进行的,很容易进行批处理。
最后是合并。为了便于管理,我合并的时候都合并到一个「人名列表」,这个列表类似下面的样子:
1 | 13 1711005017 徐小 制药1701 |
假设人名列表是name.txt,作业是1.txt、2.txt和3.txt,那么命令是
1 | join 1.txt 2.txt | join - 3.txt > 3homework.txt |
第一句那么写是因为join一次只能合并俩文件。我解决不了的问题是出来的文件把学号放最前面的,这个还得再研究。
Todo: 写个bash脚本让合并能自动进行。
筛选数据
如果我想知道分数在70到80分之间的同学的人数,应该怎么做呢?可以用Octave做,代码是
1 | score = [60 70 85 70 78]; |
画图
这里画图是为了分析学生的成绩,所谓的「成绩分析」是也。我个人不喜欢R,所以总想用Octave实现R里的那些功能。虽然Octave的统计分析功能比Matlab弱,比R更是弱的多,可对于画个直方图再拟合一个正态分布的需求还是可以满足的,效果如下图所示。
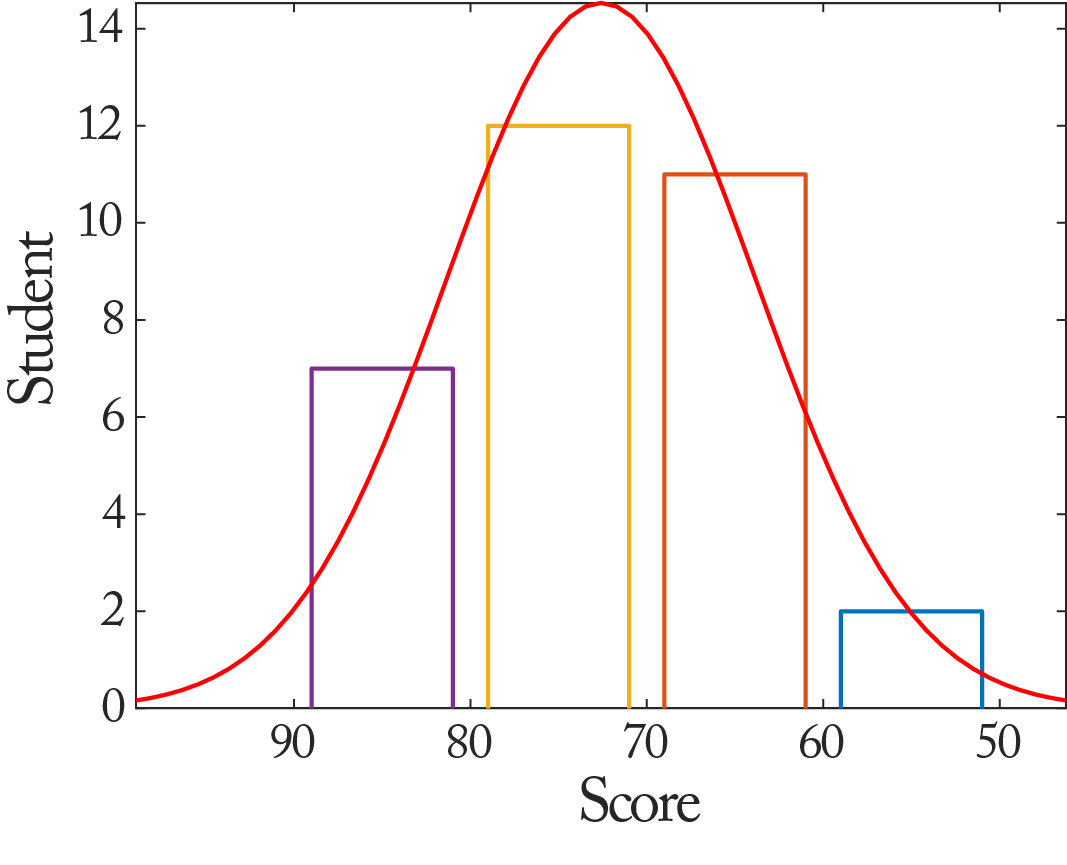
Octave的statistics包里有个函数histfit专门做这种图的,用起来也简单,比如对一系列成绩,画上面的图的代码是
1 | pkg load statistics |
上面的代码需要对histfit函数做一些修改,我已经改了,但没写文档,如果有可能的话可以贡献给社区。
上面的代码还演示了如何改x轴的方向。
统计
成绩统计没有什么复杂的,无非是平均分、标准差、各区间的人数,可以写个函数自动化:
1 | function mygrade (n) |
注意,里面对于某些特殊分数的同学进行了处理,把他们的成绩提高一点,画图的时候和我们的习惯一致。
示例输出如下,可以直接拿来用。
1 | Avg: 72.400000 |
有了这个函数可以做一些高级的事,比方说把不同班上下学期成绩放一张图里:
1 | r = 2; |
需要注意的是最后输出的地方指定了图的大小,这里必须加引号,文档里强调了。
或者您可以把评论发在别处,添加指向本页的连接,然后把网址告诉我:
本文标题:放逐Excel:将Emacs、Coreutils和Octave用于学生的作业成绩管理
文章作者:Chris
发布时间:2018-06-12
最后更新:2022-03-23
版权声明:本博客所有文章除特别声明外,均采用 CC BY 4.0 许可协议。转载请注明出处!
分享